Dazbo's Acme Blogging App on Google Cloud
Acme Blogging App Hosting on Google Cloud Platform

High Level Design
Sections in this Page
- Architecture
- Foundation and Infrastructure-as-Code
- Observability
- Migration and Decommissioning
- Still To Do / Future Work Considerations
- Parked / Deprecated
Architecture
Component Overview
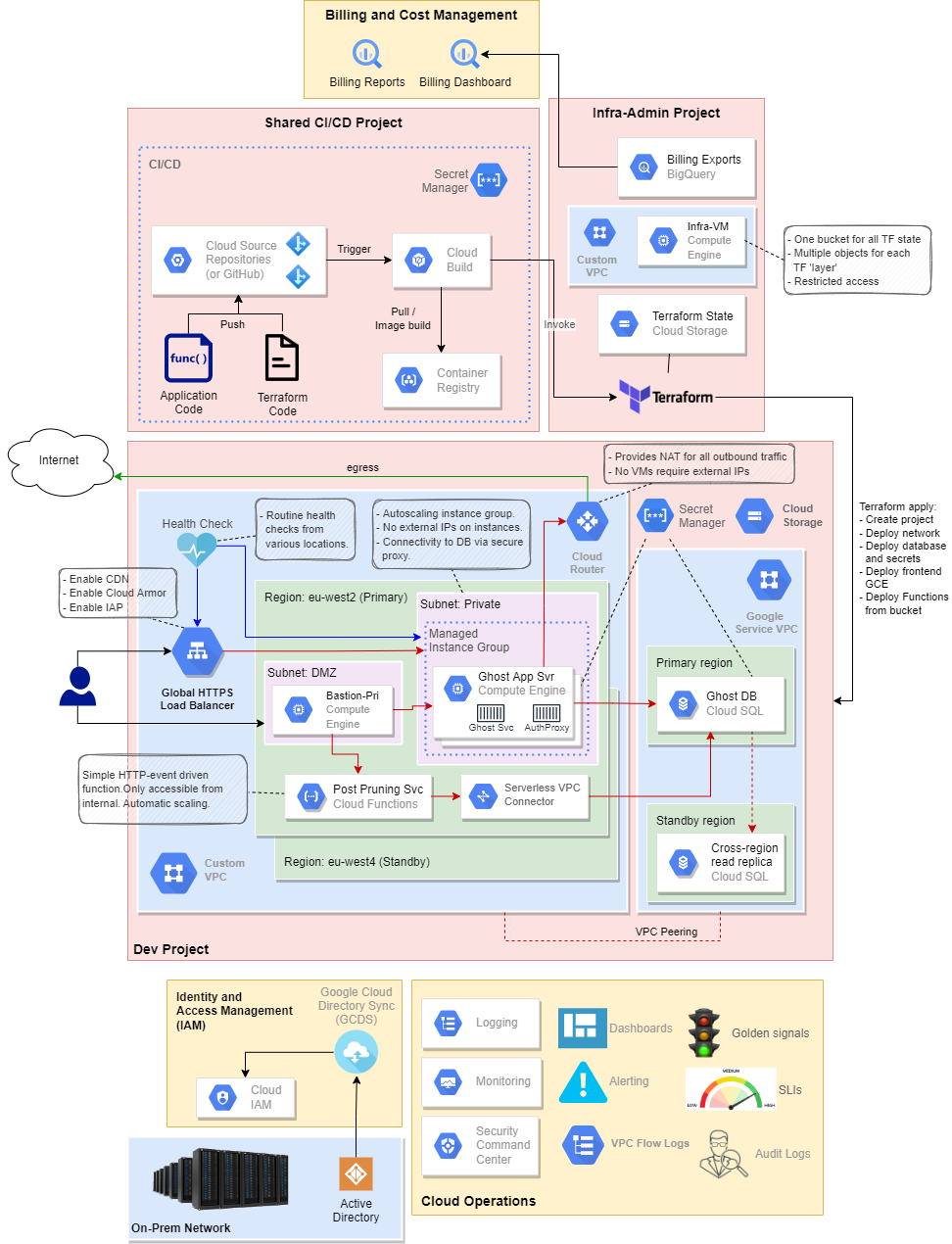
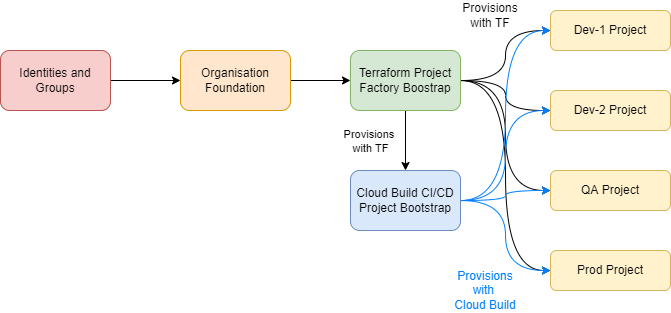
Google Organisation Resource Hierarchy
The resource hierarchy will be provisioned as shown here:
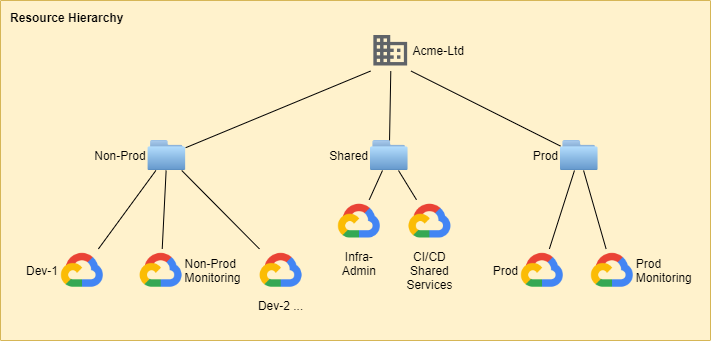
This provides:
- Simplified administration.
- Each environment (i.e. resources for a dedicated team or testing phase) will be provisioned in its own GCP project.
- Isolated projects for individual DevOps teams. This gives them autonomy over their own projects. Each of these projects will own their own resources, including VPCs and deployed applications.
- Non-production projects/environments separated from production projects/environments.
- Separate billing at project level. Thus, we can see the cost of the resources used by each DevOps team.
- Policies can be applied from the top, using the principle of least privilege.
The folders are organised as follows:
- Shared contains projects that provide shared resources. E.g.
- The Infra-Admin contains the Terraform-based Project Factory.
- The Shared CloudBuild projects contains the CI/CD Pipeline for deploying application services.
- Additional shared services could be deployed, but are not currently in the scope of this PoC. Such services include:
- Shared VPC
- Interconnect to on-premises networks
- Non-Prod contains separate projects for:
- DevOps teams / environments
- QA environment
- A monitoring project for each environment
- Prod
- The production environment
- Associated monitoring project
Identity and Access
- Identities will be managed using Google Cloud IAM. IAM ensures granular control of access to cloud resources. It will also be leveraged to restrict application access, e.g. using the Cloud Identity-Aware Proxy (IAP).
- Roles (collections of permissions) will be granted to IAM groups, rather than to individuals. This simplifies administration, and is safer. For example, the Security Ops team will be given specific roles. Predefined (aka curated) roles will be used where possible. Basic (aka primitive) roles will be avoided, as they lack granularity and apply to all resources in any given project.
- Deployment of cloud infrastructure resources will be done using automation, using service accounts with appropriate roles. This will allow projects/environments to be created in a repeatable manner.
- For the purposes of this proof-of-concept, administration of identities and groups will be done using Google Cloud Identity. However, it is expected that the final solution will leverage Google Cloud Directory Sync (GCDS) to perform a continuous one-way synchronisation of on-premises identities from Active Directory or other existing LDAP identity provider.
- For the purposes of ths proof-of-concept, authentication will be achieved using Cloud Identity. This allows multi-factor authentication (MFA). However, when integrating with an existing identity ecosystem, authentication can be integrated with an existing SAML2-compliant SSO provider, e.g. Okta, PingAccess.
Users and Clients
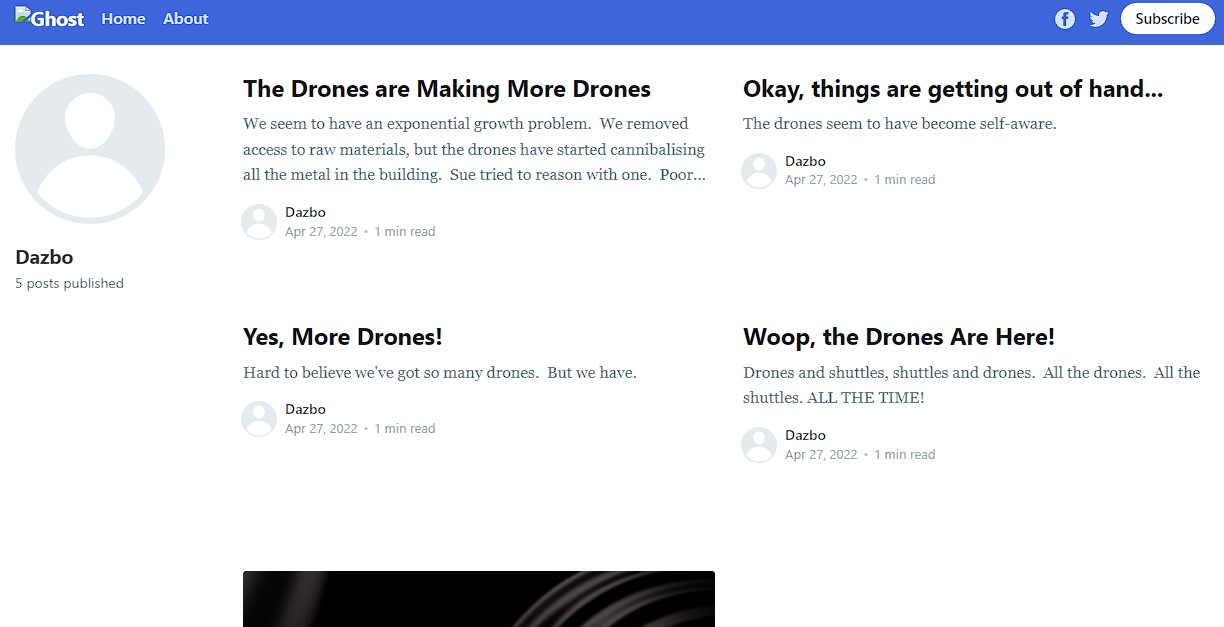
- The Ghost blogging application will be accessible to any user on the Internet through a standard web browser. There is no need to deploy client applications. Here is what the deployed application looks like, from a browser:
- Access to the Post Pruning service is only possible from the internal network, i.e. using the bastion deployed to the VPC. From there, a developer can invoke the function using a
cURL.
Applications Overview
The Ghost Blogging Application
- This application will be deployed onto Google Compute Engine instances, using an instance template and regional autoscaling managed instance groups.
- To ensure consistent state between the various Ghost instances, a Cloud SQL MySQL database will be used. (This is a fully-managed implementation.)
- The GCE instance template will contain:
- The Ghost installation, deployed as a custom Docker image from the Google Container Registry.
- The Cloud SQL Auth Proxy, deployed as a Docker image from from the Google Container Registry. This is to allow secure connectivity to a Cloud SQL database backend, without providing the Cloud SQL instances external IP addreses. This is run as a background process on the instance.
- The two containers are deployed side-by-side, using a Docker Compose configuration.
Note: according to Ghost documentation, Ghost is always intended to be deployed on a single instance. Unfortunately, the design of Ghost itself is not readily compatible with a highly-available deployment pattern, even when pointing Ghost to a database backend. Thus, whilst the design described here does work and meets the brief, it has required considerably more effort than a ‘well-behaved’ stateless application.
The Post-Purging Application
- The brief requests that this is deployed as a serverless function.
- As a result, there are limited options for securing the use of the function. I have elected to deploy the function such that it is only accessible from the internal network, e.g. using a bastion host. This means that it can only be invoked by developers who have access to the bastion.
- Running from the Internet:

- Running from the bastion using a
cURL:
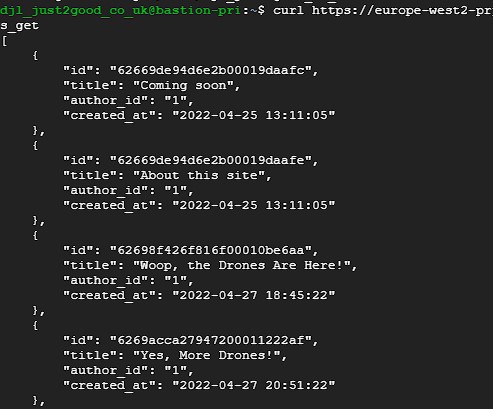
- Running from the Internet:
- (An alternative design option would have been to use a global external load balancer, using IAP to authenticate users, and pointing to a serverless NEG backend. But this seems unnecessarily complicated and expensive.)
- The serverless function requires access to the backend Cloud SQL database. For this, the architecture utilises a serverless VPC connector.
- Two functions have been deployed:
- A function to retrieve current posts and display them in JSON format.
- A function that purges all posts in the database. (Always take a backup before invoking!)
- The functions can be deployed manually. However, it is expected that in general use, Cloud Build will monitor for changes in the functions’ source code, and a trigger will redeploy the functions (using Terraform) when any changes are detected.
Security
This design deploys tiered security:
- The applications will be deployed into serverless environments, with no external IP addresses. External connectivity will be achieved through a global HTTPS load balancer.
- The load balancer provides:
- A Google-managed SSL certificate to ensure encryption between the client and the load balancer.
- Identity-level access control, using the IAP.
- Layer 7 (web) application firewalling, with preconfigured rules to mitigate OWASP Top 10 threats, by enabling Cloud Armor.
- Whilst the Google frontend can absorb a significant amount traffic and thus already significantly mitigates denial of service attacks, DoS protection can be bolstered by:
- Enabling Cloud Armor, which bolsters distributed Denial-of-Service (DDoS) protection.
- Enabling Cloud CDN, which not only caches content closer to the users, but also absorbs traffic before it reaches the load balancer.
-
The Identity Aware Proxy (IAP) provides centralised authentication and authorisation for applications accessed over HTTPS. It ensures cloud resources can only be accessed by authenticated identities with appropriate roles assigned.
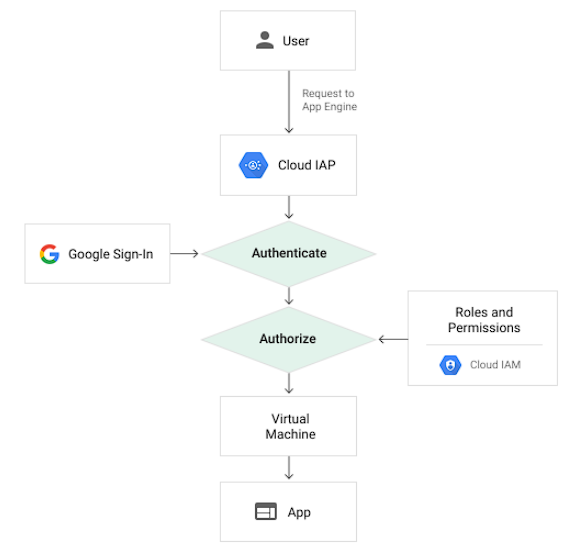
- All data at rest is encrypted by default, using AES256, with Google-managed encryption keys.
- No VM instances will be deployed with external IP addresses.
- Any engineering administration can only be carried out with VPC-specific bastion hosts. Engineers can SSH to these machines, but only by tunnelling over HTTPS and after being authenticated by Identity-Aware Proxy. Note: even these bastion servers have no external IP addresses!
- All instances (e.g. the bastions) will be deployed using a hardened OS, using virtual TPM, integrity monitoring, and trusted boot image that are enforced using the trusted images policy.
- All environments are deployed to their own dedicated networks (VPCs). This provides network isolation.
- Cloud Functions (e.g. the post purge service) may only be invoked from within the VPC.
- The Google Cloud Firewall prevents all ingress to the networks, except through the load balancer. Within the networks, internal traffic is permitted, but can be controlled at a granular level.
- Google Private Access is enabled, such that resources with no external IP addresses are able to access Google APIs and services.
- Google Private Services Access will be enabled, such that Cloud SQL can be connected to, without Cloud SQL exposing an external IP address.
- Outbound access from instances (e.g. to install components or run updates) will be done using Cloud Router to provide a NAT default gateway.
- Newly pushed build artefacts will automatically be scanned for vulnerabilities.
- All administration and security events are captured, using tamper-proof audit logging. The Security Ops team will have access to these logs.
- Access is controlled using IAM groups and policies, as described above, following the principle of least privilege.
- No secrets will be hard-coded into any code, or stored unencrypted in source repos.
- Secrets - such as the database password - are stored securely using Google Secret Manager.
- The benefits of Google Cloud’s inherent security capabilities, including:
- Cryptographic privacy of all inter-service traffic.
- A bug bounty program.
- Physical access security to Google’s data centres, including biometrics and laser perimeters.
- Custom-designed Titan security chips on servers and peripherals.
- Aggregation of security data into a single portal, in the form of the Security Command Centre. This additionally provides automatic detection of misconfigurations and vulnerabilities.
Scalability
- The Ghost frontend will be deployed within an autoscaling managed instance group. This can scale out (or in) as needed.
- The backend Cloud SQL database does not scale horizontally, but can be sized to meet expected demand. Furthermore, it is relatively trivial to up-size an existing DB instance.
- The purge service is deployed using Cloud Functions. This is an autoscaling service. However, it is not expected that any scaling will be required, since this is expected to be a rarely-used developer interaction.
Availability
- All deployed services will be regional, rather than zonal. This means that any resource is tolerant of loss of a zone.(E.g. loss of a component, or even a data centre.)
- The Managed Instance Group deploys instances across separate zones in the region.
- The Managed Instance Group supports rolling updates. I.e. when a new instance template is deployed, new instances are deployed, and the old instances are subsequently destroyed. This ensures no downtime during application upgrades.
- Cloud Functions and Cloud Run are regional services. Consequently, it is tolerant of zonal failures.
- Cloud SQL will be deployed as a regional highly-available cluster, through use of a regional persistent disk.
Disaster Recovery and Data Protection
- All resources can be deployed to two geographic regions:
- europe-west2 - London.
- europe-west4 - Netherlands.
- Some of these resources are provisioned in both regions from the start. E.g.
- The VPCs and subnets are deployed in both regions.
- Cloud SQL will always have a second instance - i.e. a cross-region replica - running the DR region.
- For other services, to save cost, they will be deployed on-demand, in the event of DR or for DR testing. The Terraform pipeline can accomplish this in minutes. The global load balancer can be updated to point to the DR backend.
- Note that Cloud SQL standby replicas cannot be promoted to a master using Terraform. Thus, a manual step will be required during DR.
- Automated daily backups of the database are created, and persisted in multiregion storage.
- Secret Manager resources are automatically replicated between regions.
Foundation and Infrastructure-as-Code
Foundation Build
The overall deployment is split into phases, as shown here:
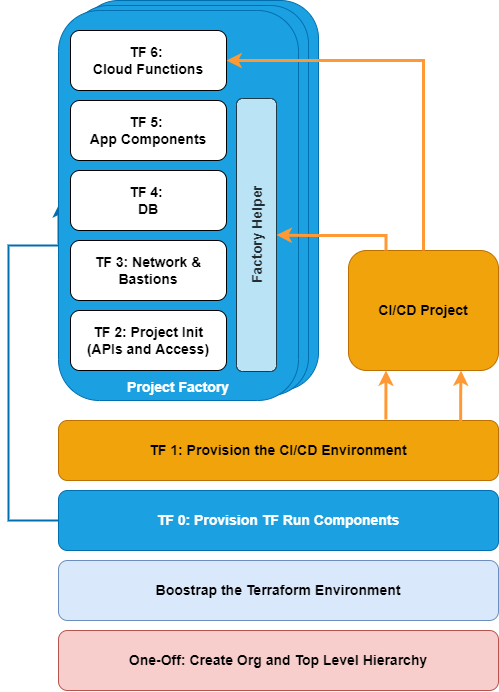
- Initial bootstrap of the organisation.
For this PoC, I’ve completed the boostrap manually. However, much of it could be automated. The bootstrap includes:- Creation of the Acme-Ltd GCP organisation.
- Creation of identities and groups, as described above.
- Creation of the top-level folder hierarchy, i.e. the Shared, Non-Prod, and Prod folders.
- Create the Shared Infra-Admin project, to host the Terraform Project Factory
- Provisioning Terraform run infrastructure for users, using Terraform itself
- Provisiong the Shared Services CI/CD project, to host the CI/CD Pipeline
Terraform Project Factory
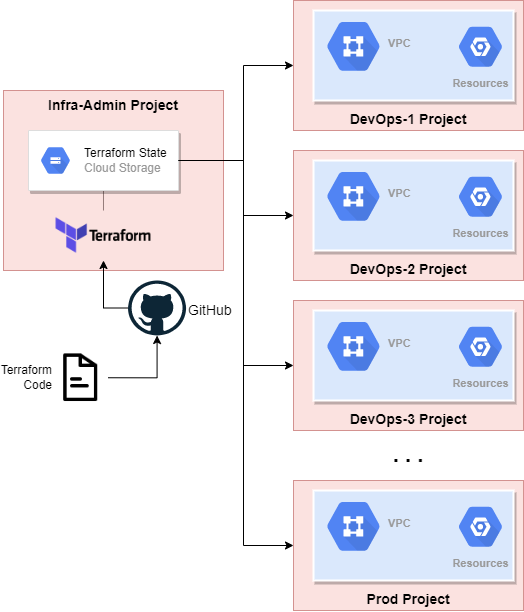
The Project Factory creates new projects, as needed. The projects include:
- Dedicated VPC network, across two regions, with subnets and firewall configuration.
- Project-specific Secret Manager and Cloud Storage bucket.
- An HA Cloud SQL database instance. (Terraform does not support promotion of a cross-region replica. This will be added manually.)
- Instances to host the Ghost application.
- A bastion host with IAP-based access. (Useful for diagnosing issues, connecting the DB, etc.)
- The Ghost application itself, in the form of a highly-available managed instance group with a global HTTPS load balancer.
This design leverages the principle of Immutable Infrastructure: cloud infrastructure resources should always be deployed using Terraform. This ensures consistency and prevents configuration drift from the design, as well as configuration drift between environments.
Terraform IaC configurations are stored in GitHub. A DevOps admin can pull from the repo, and use these configurations to spin up new projects. Each project contains everything needed for a particular DevOps team. The actual provisioning is under the control of a dedicated infra-admin service account.
As shown above, the project factory is itself split up into multiple layers:
- Each layer is itself a Terraform configuration, unique to a particular environment.
- Terraform Workspaces are used to enable easy provisioning of different projects/environments. (E.g. dev-1, dev-2, prod.)
- The configurations are intended to be run sequentially. The entire chain could be automated, but this work has not been done yet.
Having a layered factory means that each layer can be run independently. This carries advantages:
- It is faster to deploy changes.
- The blast radius of errors is smaller. At worst, we only need to tear down (destroy) a single layer.
- We can automate independent parts of the factory through the CI/CD chain. E.g. we can allow DevOps teams to run certain layers, whilst not allowing others. For example, the CI/CD pipeline can redeploy the Cloud Functions layer in response to changes in the Cloud Functions code.
- It is easy to wire all the layers to run as a single job, e.g. for initial environment provisioning.
Terraform state is persisted in a Google Cloud Storage bucket.
- This bucket is owned by the Infra project, and is secured.
- Different bucket objects are used to store the states of each layer of Terraform build process.
Cloud Build CI/CD Pipeline
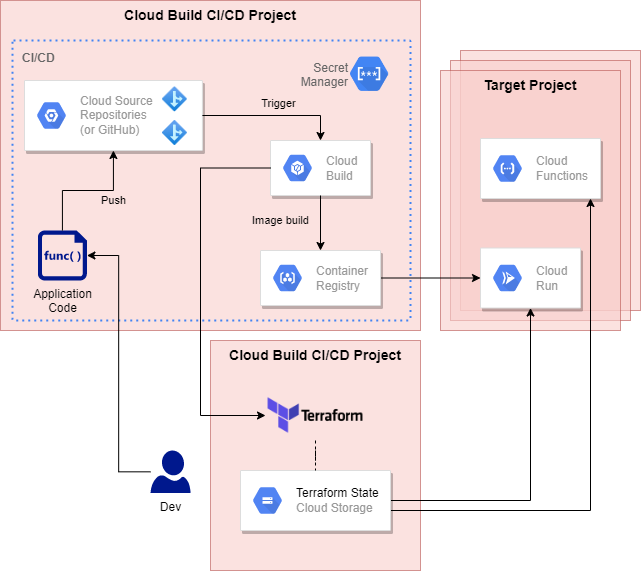
Distinct from the infrastructure provisioning process, this CI/CD pipeline enables development teams to automatically test, build and deploy, following any check-in of code.
Here I’ve elected to use a fully GCP-native pipeline for simplicity. The components are:
- Google Cloud Source Repositories:
- A fully-managed, private Git repository hosting on Google Cloud.
- Access is managed using IAM.
- Repos can be mirrored from other repos, such as GitHub and BitBucket.
- Whilst I could have used GitHub as the source of repos for this pipeline, I wanted to demonstrate a fully GCP-native approach, whilst also demonstrating separation from the Terraform project factory.
- Cloud Build:
- A managed, serverless, cloud-native continuous integration environment.
- Provides the ability to pull code in response to code changes, fetch dependencies, run unit tests, and then create build artefacts, such as Docker images or Java archives.
- Cloud Container Registry:
- A secure, private cloud-hosted Docker image repository.
- Able to perform automatic vulnerability scanning on newly pushed container images.
Observability
Monitoring and Alerting
- All monitoring, alerting and dashboards will be provisioned using the Google Cloud Operations Suite.
- Under the
non-prodfolder, a dedicated monitoring project will be provisioned for monitoring all non-prod projects and resources. - Under the
prodfolder, a dedicated monitoring project will be provisioned for monitoring all production resources. - See Operations and Observability to see a more detailed view of the alerting, metrics and custom dashboards that have been built.
Billing
See Billing and Dashboards for a more in-depth view of how this has been implemented, including some of the sample reports and dashboards that have been created.
- Billing Administration is only possible by members of the gcp-billing-admins group.
- Read-only billing visibility is currently provided to the gcp-project-viewers group, for convenience. (Through the Billing Account User role.)
- Furthermore, groups and identities can be given access to billing information related to their projects, without giving access to entire billing account.
- Resources are labelled. Currently by application name, component type, development team, by environment (e.g. dev-1, dev-2, etc), and by environment category (e.g. Non-Prod and Prod). Other labels could be added. This screenshot demonstrates how such views can be filtered:
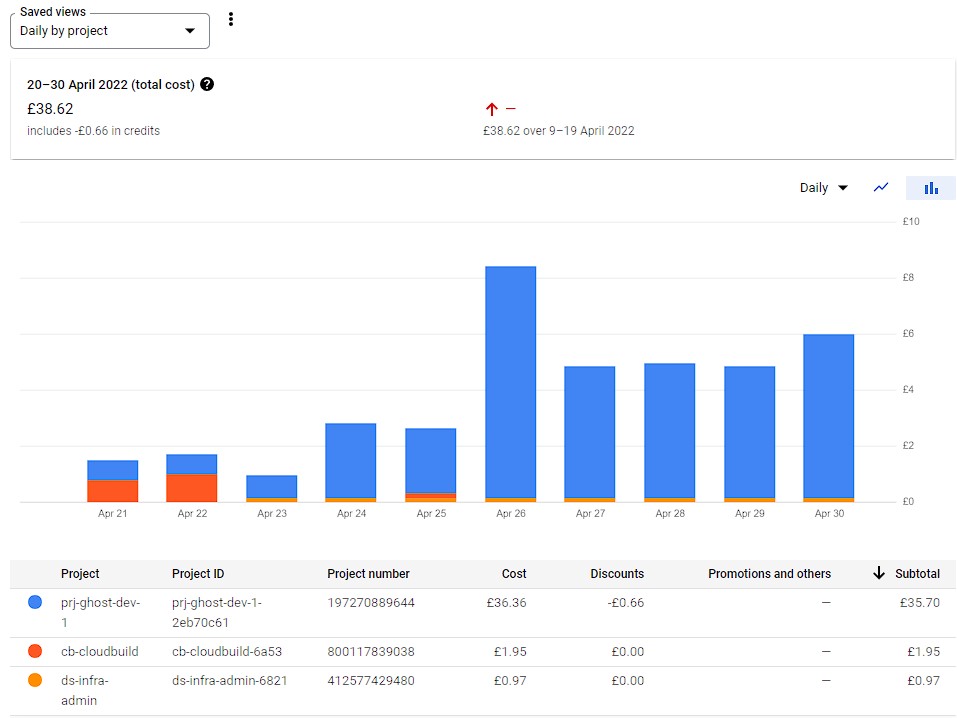
- Billing alerts are configured at 50%, 75%, 90%, and 100% of specified threshold, with email alerts going to billing admins and billing account users.
- Billing exports have been enabled, meaning that billing data is automatically exported to Google BigQuery. From here:
- Direct analytics can be performed, e.g. using SQL queries.
- Billing dashboards can be created, e.g. using Data Studio.
Cost Management
- Autoscaling means only paying for the compute that is used.
- Cost-optimised E2 machine types are used in non-prod environments. More performant N2 machine types are used in Production; these machine types also benefit from automatic sustained-use discount. Furthermore, committed-use discounts can be applied, if a 1 year or 3 year commitment is possible.
- Bastion machines should be turned off except when needed.
- Environments should be torn down when not in use.
Migration and Decommissioning
-
Whilst the entire solution is cloud-native in GCP, the solution is not locked-in to Google. If there were ever a need to migrate the solution to another hosting venue, this would be easily achieved. For example:
- The Ghost app runs as a Docker container. This could be deployed into various container hosting environments, and into different clouds.
- The Cloud SQL database is a fully-managed wrapper around MySQL. It would be simple to export this data to another hosting venue.
- The project factory is built using Terraform, which is a cloud–agnostic infrastructure automation tool. However, the specific resources and modules used within the TF configurations are Google Cloud-specific. That being said, there are comparable resources and modules available with other tier 1 cloud providers, such as Microsoft Azure and AWS.
- The CI/CD pipeline has been built around Google’s Cloud Build product. Moving to another cloud, this chain would need to be refactored. For example, a similar pipeline could be built using GitHub and Jenkins, or using a platform such as GibLab.
Still To Do / Future Work Considerations
- Integrate with existing AD.
- Integration with existing SSO.
- Automate the Terraform pipeline, e.g. using GitHub Actions or Terraform Cloud.
- Reconsider regions based on environmental impact.
- Refactor Terraform to deploy as two separate regional stacks. (Except for the DB.)
- Introduce Cloud DNS in front of our LB.
- Make Cloud DNS authoritative for our domain and create NS records with our registrar to our Cloud DNS zone.
- In response to DR, deploy second stack. Update DNS A records to point to the new LB in front of the new MIG.
- Switch from global to regional LBs. Then we can use standard network tier rather than premium.
- Creation of custom IAM roles.
- Implement Cloud Security Scanner to perform vulnerability scanning of deployed applications.
- Implement Forseti Security, to assess policies and resources and make recommendations.
- Configure log sinks for logging aggregation, retention and analysis.
- Ghost internal configuration expects the end-user URL of the site. However, Ghost expects that the URL will point directly to a Ghost instance, not to a load balancer that can point to a different instance. This is problematic if we implement SSL on the load balancer but not on the clients. The clients will force a 302 redirect, and this error breaks the HTTPS health check.
- Ghost look and feel is stored on the file system, not in the DB. To be able to change this, we need a regional storage solution. Options include:
- A regional persistent disk shared between all the instances in the template.
- Fully-managed NFS, in the form of Google Cloud Filestore.
- Using a Cloud Storage bucket, using a storage adapter.
- We’ll need to back up the NFS volume, and restore it in the event of deploying second stack.
- Switch Cloud SQL from Legacy HA to newer mode, i.e. where we simply define as regional, rather than having read replicas.
Parked / Deprecated
- Originally I had implemented Ghost as a Docker container deployed using Cloud Run. Although I was able to configure Cloud Run to connect to the Cloud SQL DB backend, I was unable to configure the Ghost application to correctly use this connection. Thus, given time available, I abandoned this approach and instead switched to deploying Ghost within GCE instances in a managed instance group.